FCN & SegNet & U-Net
语义分割大多数方法都是基于FCN改进的
Review FCN
- 全连接->卷积 任意输入
- softmax 逐像素预测类别
- Deconv 上采样
- centor crop + skip +逐像素相加 融合
语义和细节特征
Segnet
A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation

Outline
- 对称的 编码-解码 结构简单优雅
- 编码部分特征提取 VGG16的前13层,去掉了最后的3个全连接(同FCN)
- 解码部分上采样特征到原图大小,实现逐像素类别预测即分割
- 上采样使用对应下采样时最大值位置记录的索引
编码和解码都是通过卷积实现的,全程的卷积都是3x3,stride=1,oadding=1即保持图像输出大小不变
Baseline

Punchline

- 每次max pooling操作保存一个2-bit图每个位置是2x2窗口中保留元素的索引,并将这个索引矩阵传入对应的上采样层

因此上采样是不需要学习的,通过上采样得到了稀疏的特征图,但需要学习卷积层参数,通过卷积将其稠密化!
网络的参数量少!
Details
-
使用BN改变数据分布,归一化加速收敛
一般在卷积后,激活前使用BN,即Conv+BN+ReLu
BN在训练时不改变卷积的结果(有待学习!) -
在上采样部分,卷积操作不使用偏置和ReLU
- 上采样过程,就是通过卷积将稀疏的特征图稠密化,ReLU激活引入非线性时产生很多0稀疏化了结果,起了反作用,因此不需要ReLU
- 偏置其实可以看做ReLU作用的阈值,没有ReLU自然不需要偏置,总体都加上一个常数但没有ReLU操作,这个值就没有起到是否需要激活的作用,所以加不加没有区别
-
逐像素softmax,都使用交叉熵损失
softmax中有类间竞争,因此交叉熵直接对真值类预测的概率做惩罚即可
-
Bayesian SegNet 在卷积层中多加了一个DropOut层
- Dropout层:防止过度拟合,增强学习能力。
随机使部分神经元不工作(权值为0)结果是这次迭代的向前和向后传播只有部分权值得到学习
Bayesian SegNet中,作者把概率设置为0.5
Benchmark
| 度量标准 | 含义 |
|---|---|
| global accuracy (G) | 在数据集上总体的准确率 |
| class average accuracy (C) | 平均每个类别的准确率 |
| mean intersection over union (mIoU) | 类平均IoU |
| BF | 图像的F1测量平均值 |
miou更倾向于边界平滑的预测- F-measure
$F_\beta(t) = \frac{(1 + \beta^2) \cdot TP(t)}{(1 + \beta^2) \cdot TP(t) + \beta^2 \cdot FN(t) + FP(t)}.$
Experiments


U-Net Preview
Convolutional Networks for Biomedical Image Segmentation
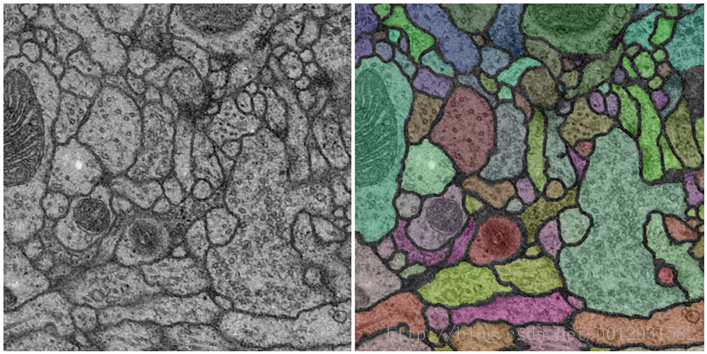
适用于医学图像分割
Baseline
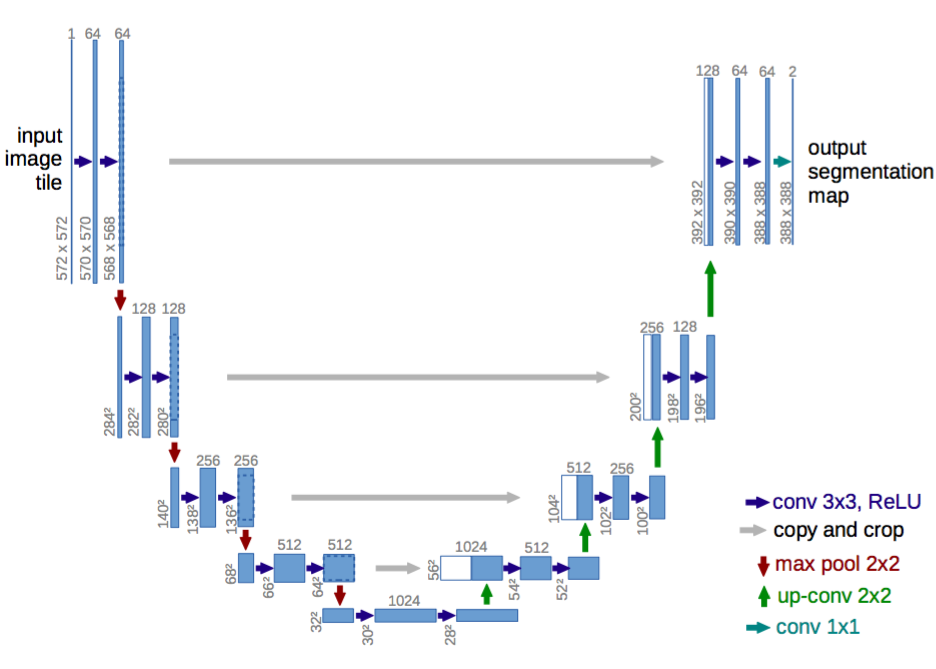
Details
- 高低层特征融合不是相加,而是concate,即通道叠加
- 输出图像小于输入图像,centor crop 保留边界信息
- 损失函数加入像素点到所在类边界相对距离的判断,对于离边界近的像素误判的惩罚更大
- 由于医学图像较大,采用裁图训练测试,并适当扩大边界,输出小于输入,但输入对于原图是有重叠的,以此保证原图被覆盖
Appendix
- Conv2d输出计算:
$ H_{out} = \left\lfloor\frac{H_{in} + 2 \times \text{padding}[0] - \text{dilation}[0] \times (\text{kernel_size}[0] - 1) - 1}{\text{stride}[0]} + 1\right\rfloor $
$W_{out} = \left\lfloor\frac{W_{in} + 2 \times \text{padding}[1] - \text{dilation}[1]\times (\text{kernel_size}[1] - 1) - 1}{\text{stride}[1]} + 1\right\rfloor$
-
ConvTranspose2d输出计算:
Input: Output:
-
反卷积的输出:
-
pytorch中的反卷积(转置卷积)
class torch.nn.ConvTranspose2d(in_channels,#输入特征的通道
out_channels, #卷积产生的通道数
kernel_size,#卷积核大小
stride=1,#步长,一般都是1
padding=0, #卷积步长即内部填充0的行列数,相当于卷积中的步长
output_padding=0, #输出补零
groups=1, #分组归一化,一般取1即输入直接归一化到输出
bias=True, #添加偏置
dilation=1) #卷积核元素间距,大于1时为空洞卷积(膨胀卷积)
- With square kernels and equal stride
m = nn.ConvTranspose2d(16, 33, 3, stride=2)
- non-square kernels and unequal stride and with padding
m = nn.ConvTranspose2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2)) input = torch.randn(20, 16, 50, 100) output = m(input)
- exact output size can be also specified as an argument
input = torch.randn(1, 16, 12, 12) downsample = nn.Conv2d(16, 16, 3, stride=2, padding=1) upsample = nn.ConvTranspose2d(16, 16, 3, stride=2, padding=1) h = downsample(input) h.size()
Output: torch.Size([1, 16, 6, 6])output = upsample(h, output_size=input.size()) output.size()
Output: torch.Size([1, 16, 12, 12])
SegNet 原文地址 A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
U-Net 原文地址 Convolutional Networks for Biomedical Image Segmentation