An Analysis of Scale Invariance in Object Detection - SNIP
0. Introduction
-
目标检测中的矛盾
分类网络的位置不变性:
对分类任务而言,希望网络随着某个目标在图像中移动,无论移动到哪里都依然可以准确的区分为对应的类别,实验表明,深的全卷积网络能够具备这个特性,比如ResNet-101
检测网络的位置敏感性:
对检测任务而言,希望网络准确的输出目标所在的位置,随着某个目标的移动,网络输出的框能和它一起移动,依然可以准确的检测到它,即对目标位置的移动很敏感,但深的全卷积网络不具备这样的特质……
-
目标检测比图像分类难
目标实例的大尺度变化,尤其是检测非常小的目标
两个任务常用的数据库比较:ImageNet图像分类; COCO目标检测

RoI: Region of Interest (目标区域)
横坐标:roi大小相对于图像尺寸的比例
纵坐标:roi个数占数据库中的比例
曲线表示,图像尺寸中的占比小于等于某个数值的roi在整个数据库中的占比
- COCO:近一半roi小于图像的0.1, 10%的roi只有图像的0.01,最小的前10%和最大的后10%的roi尺度相差接近20倍
- ImageNet:相对均匀一些
因而使用ImageNet分类网络的预训练模型时,有严重的domain-shift问题
domain-shift 任务迁移之间的代价,目标是减小
为缓解尺度变化和小物体检测的问题,几种现有方法:
- 融合浅层低分辨率特征到高层特征中来检测小物体
- 使用可变形卷积或扩展卷积(膨胀卷积)来增大感受野
- 使用不同深度、分辨率的特征层各自独立预测不同尺度的目标
- 引入“上下文”(邻域信息)来辅助学习消除歧义
- 多尺度训练,多尺度图像金字塔做推断,再使用NMS融合筛选结果
以上这些结构上的创新都在目标检测都有重要意义,但是这些改进有效的原因并不明确,作者做了一系列对比实验来证实其作用并解决了以下问题:
上采样(即放大图像)对检测的性能提升是必要的?
- 一般480x640要上采样到800x1200
- 可以在CNN上以更小的步长即放大较小倍数用ImageNet分类数据库中的低分辨率图像训练然后在目标检测数据库上微调(fine-tune)来检测小物体吗?
- 对于使用预训练的图像分类模型fine-tuning的目标检测器,用于训练的目标尺寸是否需要严格限制在一定范围内(64x64 到 256x256)吗?
论文第2部分介绍相关工作,第3、4、5部分是对比实验
第6部分,作者才提出了一个新颖的训练范式,SNIP( Scale Normalization for Image Pyramid )
- 在训练中减少尺度的变化还不需要损失训练样本
- 使用图像金字塔获得尺度不变性(而不是尺度不变的检测器) 图像金字塔包含:在多尺度中的一个尺度上归一化表示的目标实例
- 只反传与预训练数据分辨率相近的roi的梯度
高效的利用了所有目标样例训练,通用并可嵌入其他任务的训练pipeline

1. Key-points
-
Deformable Convolution 可变形卷积
通过添加一个卷积层学习普通卷积核采样的位置使其不仅限于规则格点,而是在当前位置附近随意采样,感受野更大,形状更灵活

-
R-FCN 全卷积 位敏得分图
将Faster R-CNN的RoI Pooling改进为学习了相对位置信息的位置敏感得分图用于第二阶段的分类和回归

-
Image Pyramid 图像金字塔
使网络具有尺度不变性的两类策略
传统的图像金字塔:
将检测问题转换为固定大小的输入图像的分类问题(对于每张输入图像转化为不同尺度,建立图像金字塔)在每个尺度的图像上,使用固定大小的检测器比如滑窗或级联的分类器来做分类
特征金字塔:
使用多尺度特征图,比如SPP-Net和FPN,其中FPN可以算是目前检测算法中的标准组件了
下图a表示IPN,d表示FPN,
b表示一般的卷积提特征后的预测,SSD就类似c中的思想,使用多尺度特征图做独立预测最后融合

2. Related Work
学习具有尺度不变性的表示对于识别和定位目标是非常重要的
-
CNN中越深的层对原始输入图像的表示越粗糙,使得小物体的检测非常困难:一般的,小物体在具有更高分辨率的更浅的特征图(conv3)上训练,大物体在具有更低分辨率的更深的特征图(conv5)上训练
-
使用扩张卷积来增大特征图的分辨率,且可变形卷积保留了预训练网络的权重和感受野,在大物体的检测上表现也没有退化
-
虽然FPN融合深浅层特征得到了更高层的语义信息,但是对小物体的检测依然比不上图像金字塔IPN
(一个目标是25x25像素的,在训练中上采样2倍后,也只有50x50,一般预训练网络的输入图像分辨率是224x224)?下图说明:对于同一张图在输入尺度不同时,即使在同一卷积层,特征的语义区域对应的信息也不同,因此FPN是不够的,对于大小物体还是要在输入图像尺度上变化,即需使用IPN

3. Experiments & Results
3.1 训练和测试的尺度问题:
训练800x1200,显存限制,不能更大了
测试1400x2000,提升小物体检测

伪高清:分辨率还是224x224,但是由低分辨率上采样得到的(比较模糊,细节等高频分量还是低分率的水平)
-
CNN-B:原图训练224x224、伪高清测试
在224x224尺度上训练,stride=2. 将测试图像下采样到 [48x48, 64x64, 80x80, 96x96,128x128], 然后再上采样(放大)回224x224用于测试,结果如图:
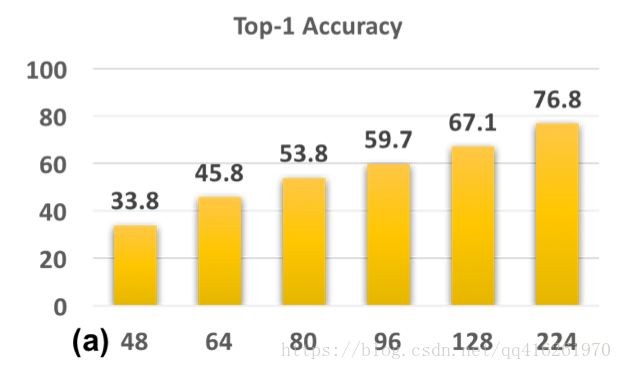
结论: 训练测试尺度差距越大(实际上是清晰度的差异越大), 检测性能越差
因为没有使用和训练尺度相互匹配的尺度进行测试(清晰度), 使得模型一直在sub-optimal发挥
-
CNN-S: 低清训练 、低清测试
根据上一个实验的结果, 做一个训练测试尺度匹配的实验,选取48x48作为训练测试的尺度,且stride=1(因为如果不修改stride,图像太小,经过几次pool后就没了)
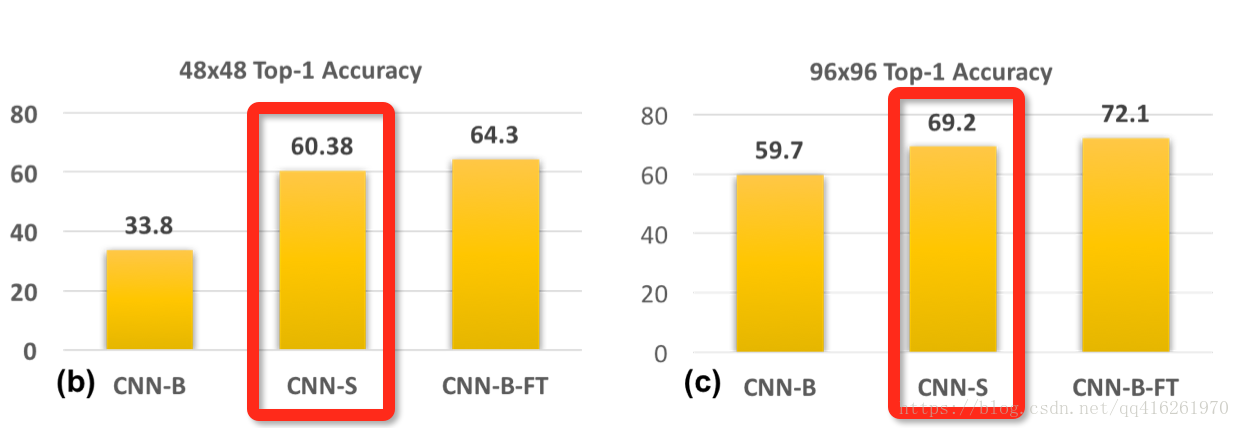
结果:训练测试的尺度匹配后, 性能大幅提升, 同样将48换成96也得到一致的结果
-
CNN-B-FT: 原图训练、 伪高清微调 、伪高清测试
为了在伪高清尺度测试, 把由原图训练的CNN-B用伪高清图像去做微调
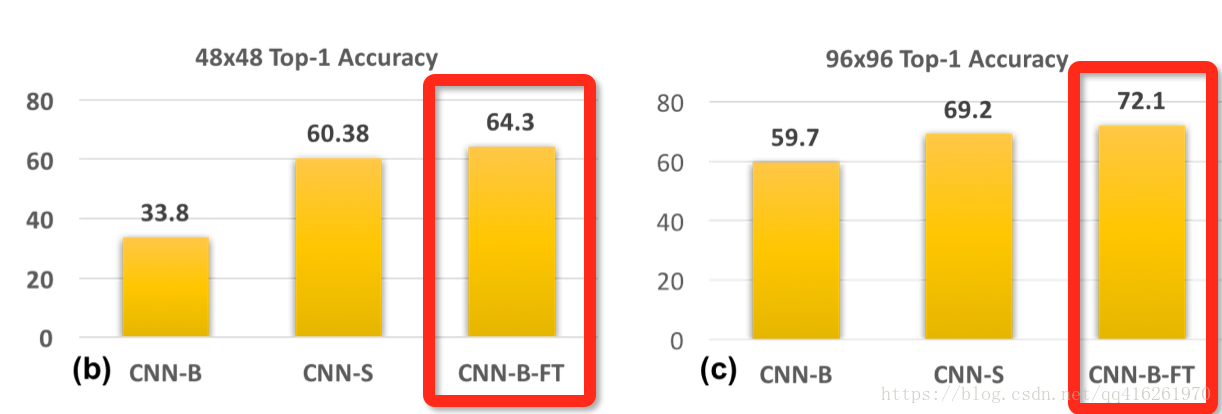
结论:CNN-B-FT的结果最好,优于CNN-S
- 从CNN-B-FT的实验可以得出: 用高分辨率训练集学出来的模型依然有办法在低分辨率图像上采样得到的伪高清图上做预测,且直接用低分辨率图像上采样微调优于将stride降低重新训练一个模型
- 推广到目标检测上, 当尺度不同时, 可以选择更换在ImageNet上预训练的基础网络骨架,或直接使用同一个网络,因为在分类任务上学到的大目标预训练模型有助于小目标的分类
3.2 分析尺度变化
数据库中原图尺寸为640x48, 小物体是小于32x32的物体,测试一般使用1400x2000
- 实验 800all VS 1400all
- 实验设置: 选用800x1200和1400x2000两种训练尺度;测试时, 都使用1400x2000的尺度.
- 结果比较:
| 800all | 1400all |
|---|---|
| 19.6 | 19.9 |
与之前实验分析的一样, 当训练测试尺度一致时, 得到的结果最好,所以1400~all~更优
问题: 为什么只超过了一点点?
因为在考虑小物体的分类性能而放大图像的同时, 也将中/大尺度的样本放大得太大, 导致无法正确识别
- 实验 140<80px
- 实验设置: 用了大图, 却被中/大尺寸的样本破坏了性能, 那么就只用尺寸小于某阈值的样本进行训练, 即在原图尺寸中>80px的样本直接抛弃, 只保留<80px的样本参与训练.
- 结果比较:
| 1400<80px | 800all | 1400all |
|---|---|---|
| 16.4 | 19.6 | 19.9 |
跟预想的不一样, 性能下降很多,根本原因:这种做法抛去了太多的样本(≈30%), 导致训练集丰富性下降, 尤其是抛弃的那个尺度的样本(中/大尺寸)的检测没有得到足够的学习
- 实验 多尺度训练(MST)
- 实验设置: 多尺度训练保证了各个尺度的样本,都有机会被缩放到合理的尺度区间参与训练.
- 结果比较:
| 1400<80px | 800all | 1400all | MST |
|---|---|---|---|
| 16.4 | 19.6 | 19.9 | 19.5 |
最终性能和800all 没太大差别, 主要原因和实验 800all VS 1400all 类似, 因为引入了极大/极小的训练样本.
” MST的做法扩充了不同scale样本的数目,但仍然要求CNN去fit所有scale的物体。通过这样的一个对比实验,SNIP非常solid地证明了就算是数据相对充足的情况下,CNN仍然很难使用所有scale的物体。由于CNN中没有scale invariant的结构,CNN能检测不同scale的“假象”,更多是通过CNN来通过capacity来强行memorize不同scale的物体来达到的,这其实浪费了大量的capacity,而SNIP这样只学习同样的scale可以保障有限的capacity用于学习语义信息。”
4.SNIP
Scale Normalization for Image Pyramids (SNIP)
- 思想: SNIP是MST的升级版,只有当目标物体的尺度与预训练数据集的尺度(通常为224x224)接近时, 才把它用来做检测器的训练样本
- 基本假设:不同尺度的物体(因为多尺度训练)总会落在一个合理的尺度范围内,对于每一个尺度,只有相对应的物体尺度的roi参与训练, 剩余部分在反传的时候忽略
SNIP pipeline, 其中RCN: Deformable R-FCN检测器
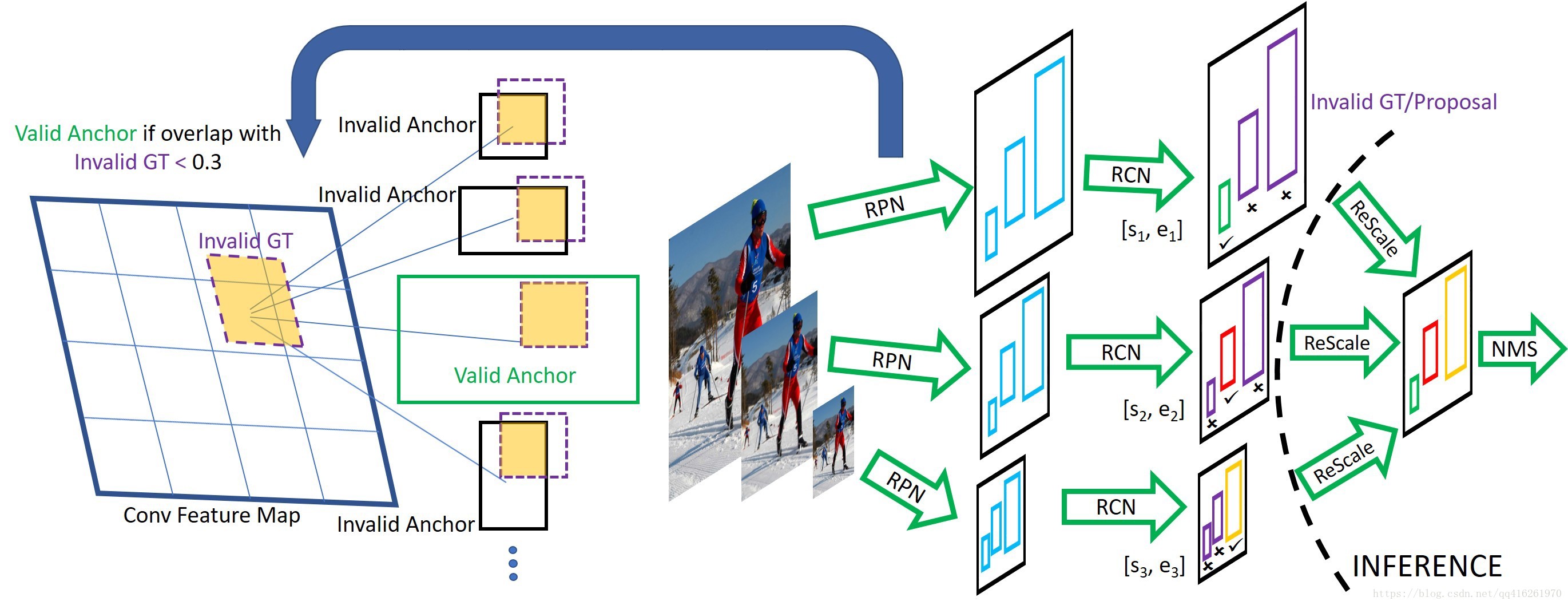
RPN阶段
- 根据第i个尺度下的valid range: **[s~i~ , e~i~], 将Ground Truth根据是否落在范围内分为Valid / Invalid GT**
- 去除IOU(anchors, Invalid GT)>0.3的anchors
FC阶段
- 用所有的Ground Truth给Proposal RoIs分配好类别标签
- 弃用不在[s~i~ , e~i~]范围内的GT和Proposals
- 全被剔除了的处理:直接忽略这个尺度下的这张图像
测试阶段
- 用多尺度正常进行测试
- 在合并多尺度Detection之前, 只在各个尺度留下满足其条件的Detection
- 使用Soft-NMS合并 (对比的其他模型有没有soft-nms?)
文章中SNIP的图像金字塔尺度为3个,分别是(480,800), (800,1200), (1400,2000),其中第一个分量为短边,第二个分量为长边的上限,分别对应RoI的范围是[120,∞],[40,160],[0,80]
思想简单,但效果好,实现细节上的优化:
-
使用Deformable R-FCN detector而不是一般卷积
-
使用的网络结构是Dual path networks(DPN)和ResNet-101,需要内存很大,为了适应GPU内存,作者对图像进行了采样,具体方法:选取1000x1000的包含最多目标的区域(chips)作为子图像,重复该步骤直到所有目标都被选取
(只对1400x2000的图片进行采样. 800x1200/480x640/图片无小物体时, 不进行采样)
-
为了提升RPN的效果,尝试了使用7个尺度,并连接conv4和conv5的输出(concatenate)
-
使用难例挖掘OHEM(Online Hard Example Mining)
-
RPN和RCN分开各自训练并评估
RPN在IOU=0.5时的准确率是最重要的,因为RPN只是提取初始proposals的,之后的二次回归会做位置精修

5. Summary
-
SNIP做的事情非常简单:
在训练中,每次只反传那些大小在一个预先指定范围内的proposal的梯度,而忽略掉过大或者过小的proposal;
在测试中,建立尺度不同的Image Pyramid,在每张图的不同尺度上都运行对应的detector,同样只保留那些大小在指定范围之内的输出结果,最终rescale到一起Soft-NMS
保证网络总是在同样scale的物体上训练,即标题中Scale Normalized
-
直击现在CNN其实仍无法解决好的一个问题:scale invariance
虽然通过FPN,Multi-scale Training这样的手段可以缓解这个问题,但还是不能通过现有CNN的框架来本质上描述,无论是使用Multi-scale Training来暴力扩充数据,还是使用FPN来融合底层和高层的不同分辨率特征,都难得到一个满意的效果
最有效的方式还是这个网络在训练和测试的时候都处理scale相近的物体,就是SNIP的思想
原文链接:
https://arxiv.org/abs/1711.08189
参考博客:
https://zhuanlan.zhihu.com/p/36431183
这是一篇很工程化的文章,作者通过大量的对比实验来证实自己的理论和观点,然后在实验结果上设计思考