Keypoints 关键点
对分类和回归使用由不同结构的网络分支提取出的不同的特征,
(其他方法对于两个任务使用共享特征,而任务的不兼容性使得表现退化)
-
回归分支通过旋转卷积核来提取对旋转敏感的特征,位置检测更精确
-
分类分支通过下采样旋转敏感特征提取旋转不变的特征,文本判断更准确
(想法可以几乎无损速度的情况下嵌入其他的检测网络中使用)
Introduction 引入
-
一般的目标检测方法都专注于检测水平方向的bounding box,对于较长且方向任意多变的目标是不适用的
-
在一般结构的CNN中,两个任务共享由于池化层下采样得到的具有旋转不变性的特征
-
具有旋转不变性的特征提升分类任务的效果,但对于需要回归任意方向的bbox是不利的,回归任务更需要的是对旋转敏感的特征
-
分类和回归之间的矛盾在具有有限横纵比的目标上可能不是太重要
-
与英文单词间有空格不同的是,中文文本通常需要行级检测,而非单个单词的定位,因此使用旋转不变的特征会阻碍这种长窄有向的bounding box的回归
池化获得具有旋转不变性的特征 ?CNN具有一定的旋转不变性(十分有限),但不是因卷积,而是因为max pooling:
- “正面拍照时,学习到的一些地方的像素点的activation(激活)会比较大,当略微转过一些角度后,使用max pooling,仍让结果在相同的地方取到最大值,所以具有一定的旋转不变性,但是对于角度很大的旋转来说,max pooling的旋转不变性也会失效,这时候就需要data augmentation”
- 更多的旋转不变性是通过在训练数据中增加旋转的图像(data augmentation)学习出来的

Related Work 相关工作
-
R-FCN提出了对分类任务有利(对回归任务不利)的平移不变性特征问题的解决方法,引入(硬学位置信息的)位置敏感得分图:
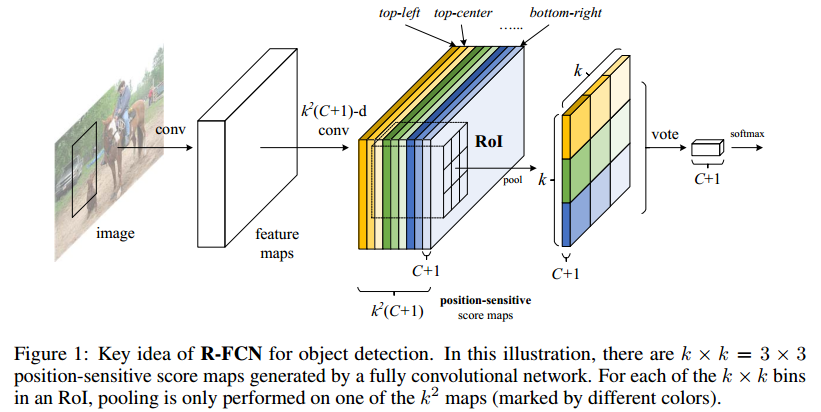


(RoI Pooling是SPP-net中SPP layer的特例,即只有一层的空间金字塔池化)
-
融合高、低分辨率的特征,即融合不同深度的特征图来平衡分类和回归之间的矛盾
-
目前场景文本检测器可以分为两种:水平和多方向,多方向文本的输出一般由有向矩形或者任意方向的一般的四边形表示,需要表示倾斜角度或者定点坐标额外的变量
-
受启发于ORN提出的在卷积过程中旋转产生的对旋转敏感的特征图
Rotation-Sensitive Regression Detector(RRD)
- 端到端
- 全卷积
- 结构受启发于SSD,使用VGG16作为特征提取的骨架网络

RSR( Rotation-Sensitive Regression ) 旋转敏感的回归
ARF(active rotating filters) 旋转滤波器:使用一个规范滤波器(卷积核)和其旋转的“克隆”对特征图做卷积。

具体的,F~j~(n)表示旋转第j个角度的第n个卷积核,M~i~(n)表示输入的特征图的第n个通道,做卷积操作,得到的输出M~o~(j)的第j个通道
k x k x N,其中k是卷积核大小,N是旋转角度的总个数,ARF通过将标准卷积核旋转到不同角度得到N-1个“克隆”版本,将N个卷积核对特征图卷积,得到N个通道的响应值,实际中设置N=8
ARF包含了更丰富的旋转信息,产生了带有旋转通道的特征图,捕捉了对旋转特征敏感的特征,提高了对旋转样本的泛化性
为使得感受野更适用于长文本,在两个分支都采用inception块,连接了由三种不同尺寸的滤波器产生的特征图,卷积核尺寸分别是mxm, mxn, nxm,其中,m=3,n=9,7,5各自对应三个阶段,inception块产生了不同长宽比的感受野大小,对于检测长文本是十分有帮助的,可用于检测行级文本,但容易漏检单词级文本(在长文本很稀少的情况下)
将RSR加入vgg16的backbone中,结构如下:

RIC( Rotation-Invariant Classification ) 旋转不变的分类
与回归不同,任何旋转角度的文本区域都应该被判断为正类,因此对于文本存在性的分类任务,需要提取一个旋转不变性的特征图

通过对上一步(ARF)得到的N个通道的旋转敏感的特征图进行下采样,即逐像素对N个通道取最大值得到M~pooling~的结果,因为pooling操作是无序的并且应用到所有N个响应特征图上,结果对于分类目标的旋转是具有局部不变性的,其中inception块的设置和回归分支是一样的
Default Boxes and Prediction anchor和预测
default box <==> anchor
B0=(x0,y0,w0,h0) 表示默认水平框即anchor,
Q0=(v10,v20,v30,v40)表示4个顶点坐标,
vi0=(xi0,yi0)表示每个顶点坐标的具体表示,其中i∈{1,2,3,4}
回归分支预测从anchor到四边形的偏移量
Q=(v1,v2,v3,v4)为预测的四边形4个顶点坐标,vi=(xi,yi)
(△x1,△y1,△x2,△y2,△x3,△y3,△4,△y4,c) 预测层输出分类得分和偏移量

其中,w0和h0分别表示anchor的宽和高
同样对于预测得到的四边形使用NMS
Training 训练
-
Ground Truth 真值标签
认真选择四边形的第一个顶点对于回归是很有帮助的,根据4点到对应的最大的水平bounding box距离来决定第一个顶点(和Textboxes++: A single-shot oriented scene text detector中选定的方式相同)
-
Loss Function 损失函数
在训练阶段,anchor与真值bbox通过重叠度做比较(IOU)
(与SSD: single shot multibox detector相同),为了计算效率,在匹配比较阶段使用最小水平外接矩形
损失函数也是使用和SSD中类似的,更具体的说,x表示匹配指示矩阵
xij=1表示对于第i个anchor和第j个真值有一定重叠度即匹配,否则xij0
c表示置信度,l表示预测的具体位置,g表示真值位置,损失函数如下:

N表示anchor与真值匹配的bbox个数,为了更快收敛取α=0.2,对于回归采用Smooth-L1损失,对于分类使用二分类的softmax损失,并且使用和SSD中相同的在线难负例挖掘(OHEM)
根据输入样本的损失进行排序,筛选出hard example,表示对分类和检测影响较大的样本,然后将筛选得到的这些样本应用在随机梯度下降中训练。在实际操作中是将原来的一个ROI Network扩充为两个ROI Network,这两个ROI Network共享参数,其中前面一个ROI Network只有前向操作(只读网络),主要用于计算损失;后面一个ROI Network包括前向和后向操作,以hard example作为输入,计算损失并反传梯度
Trick: OHEM算法通过选择hard example的方式来训练,解决正负样本类别不均衡问题同时提高算法准确率
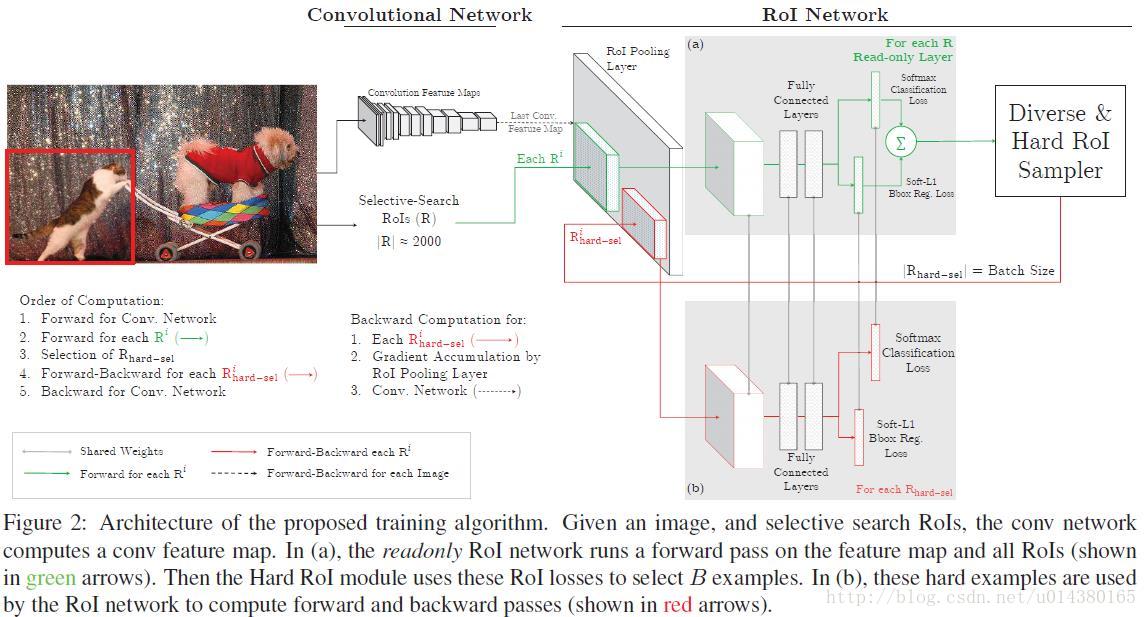
Implementation Details 实现细节
-
使用Adam优化方法
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
- 对内存需求较小
- 为不同的参数计算不同的自适应学习率
- 也适用于大多非凸优化- 适用于大数据集和高维空间
-
在SynthText库上30K次迭代与训练,并在实际数据中fine-tuning
-
初始5-10K次迭代,图像随机切割crop到384*384,学习率设为10^-4^
-
接着5-10K次迭代,图像归一化resize到768*768,学习率设为10^-5^
-
anchor比例:
数据库 比例种类
IC15、IC13 [1; 2; 3; 5; 1=2; 1=3; 1=5]
RCTW-17, RCTW-Long MSRA-TD500 [1; 2; 3; 5; 7; 9; 15; 1=2; 1=3; 1=5; 1=7; 1=9; 1=15]
-
NVIDIA TITAN Xp GPUs
-
batch size设为32
Results 结果




baseline:没有inception,且分类回归共享传统的特征图(相当于SSD)
inc:加入inception
rs: 旋转敏感回归
rotInvar:旋转不变分类




限制:
- 不能检测出一个字符间空格较大的完整的文本行所在bbox
- 将两个在一竖直文本列上的字符判断为一个水平行bbox